
I takt med att den artificiella intelligensens förmåga att generera text fortsätter att utvecklas, växer behovet av att kunna bedöma och jämföra dessa genererade texter mot ett givet mått på kvalitet. Hur kan vi effektivt utvärdera svårfångade egenskaper såsom innehållets relevans, struktur eller stilistiska precision i en text? Denna fråga fick mig att utforska några olika metoder för textutvärdering med hjälp av LLMer samt diverse mått på hur lika två texter är, med målet att bättre förstå hur vi kan kvantifiera texters kvalitet.
Intro
I en tidigare artikel (https://purpur.se/ge-ditt-foretag-ett-forsprang-genom-utnyttja-ai-for-att-svara-pa-upphandlingsforfragningar/) tittade jag på hur man kan använda LLMer för att svara på en upphandling. Med samma textmaterial som grund visar jag i denna artikel på några olika sätt som man kan jämföra texter. Varför är det bra? Jo, för att när man genererar text utifrån en viss prompt, vissa LLM-inställningar och en viss systemarkitektur (allt detta brukar kallas hyperparametrar) så kommer man att få lite olika resultat varje gång. När man försöker förbättra sina resultat så ändrar man lite på en hyperparameter och får ett nytt resultat. Om resultatet är bättre så var det troligen en bra ändring som vi vill behålla, men om det blev sämre så rullar man tillbaka ändringen och provar något annat. Men hur ska vi veta om ändringen resulterade i något bättre eller sämre? Jo, det är där som problemet med att jämföra texter kommer in.
Om vi har en fråga som vi vill att LLMen ska ge oss ett svar på (som i min tidigare artikel) så finns det några varianter:
- jämför svaren med varandra för få fram vilka svar som är bättre relativt andra svar
- jämför alla svar med ett “bra svar” som en människa sagt att -”Jorå serru, detta det är ett bra svar”.
I denna artikel kommer jag kolla på båda varianterna.
Dataset
Att mäta likheten mellan en fråga och dess svar är inte trivialt. Jag inledde experimentet med att skapa ett litet dataset med texter som varierade från välformulerat och detaljerat, till texter på ett helt annat ämne. Så här såg mitt dataset ut:
- Referenstexten
- Halvbra genererat svar
- Halvbra genererat svar
- Halvbra genererat svar
- Ogrundat genererat svar inom samma område
- Ogrundat genererat svar inom samma område
- En text inom ett helt annat ämne
Min första text i datasetet var referenstexten, dvs samma text som jag jämför alla texter med. Varför det då? Jo, för att om jag har bra hyperparametrar så vill jag så klart att den texten ska ha hög likhet med sig själv och de andra halvbra texterna.
Av samma anledning vill jag ha med en text (nummer 7) om ett helt orelaterat ämne för att kunna verifiera att med en viss uppsättning hyperparameterar så kan jag se på mätvärdet att den är helt olik de övriga texterna. Dessa två texter blir på så sätt mina fasta punkter i mätlandskapet.
Genom att använda OpenAI:s embeddings-modell, text-embedding-3-small, skapade jag embeddings för varje text och mätte sedan deras cosine similarity mot min referenstext. Intuitivt borde detta ge en siffra som representerade likheten – ju högre siffra, desto större likhet. Denna siffra borde alltså vara på topp för min text nummer ett och sedan falla till något väldigt lågt för min sista text, nummer sju.

Staplarna ser ut ungefär som vi förväntade oss, en fallande likhetsgrad med två tydliga grupper: de tre halvbra texterna och de två ogrundade texterna.
Som man ser i grafen är svaren genererade med lite olika temperaturer där en högre temperatur indikerar större frihet och kreativitet. Det verkar som om en högre temperatur, dvs ett lite mer kreativt svar, ger en lite bättre likhet med det bra svaret.
PCA
Ett annat sätt att visualisera detta på är att använda sig av Principal Component Analysis (PCA) för att minska dimensionerna och visualisera texternas inbördes placering i en 2D-graf.
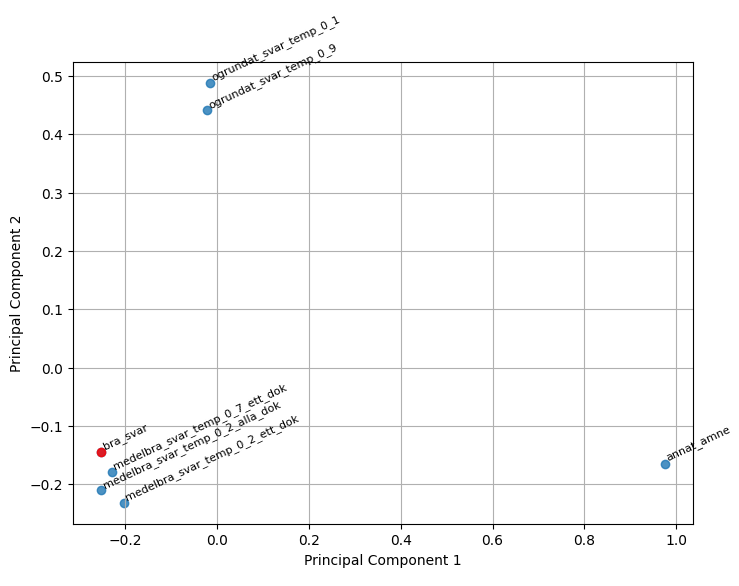
Även här syns det väldigt tydligt vilka olika grupper av texter vi har.
Vi kan alltså konstatera att med hjälp av embeddings och olika typer av likhetsmått och visualiseringar så kan vi tydligt se hur “bra” ett LLM-genererat svar ser ut relativt vårt manuellt bedömda “bra” svar.
LLM som domare
Det är svårt att jämföra texter. Men texter är ju just det som LLMer är bra på så varför inte låta LLMen själv avgöra om en text är bra eller inte. Vi kan sedan jämföra resultaten med våra tidigare försök till semantisk jämförelse, dvs cosine similarity baserat på embeddings.
Alltså tog jag ett nytt grepp om problemet genom att låta LLMen själv agera domare (engelska “LLM as a judge”) och betygsätta texternas relevans gentemot referenstexten. Genom att testa olika hyperparametrar såsom temperatur (dvs kreativitet) och prompt ska vi nu testa LLMernas förmåga att korrekt klassificera texter. Denna metod visade sig ge en mer nyanserad bild av texternas kvalitet, men också utmaningen i att finjustera prompten för att få skarpa analyser från modellen.
En nyanserad bild
Mina experiment avslöjade att medan embeddings och similarity metrics erbjuder robusta verktyg för att jämföra texter på en hög nivå, kan de vara otillräckliga för att separera mellan texter av närliggande kvalitet. Å andra sidan har en LLM-domare förmågan att dyka djupare in i texternas struktur och innehåll men kräver en välkalibrerad prompt för att producera meningsfulla och konsistenta bedömningar.
Först o främst behöver vi en bra prompt.
Du är en AI-assistent som är bra på att jämföra texter, speciellt är du bra på att avgöra hur lika texter är varandra.
---
Bra exempel på text:
{bra_svar}
---
Text som ska bedömas:
{text_att_bedoma}
---
Instruktion:
Jämför det bra exemplet på text med den text som ska bedömas.
Svara med en av kategorierna nedan beroende på hur lika innehållet i de två texterna är,
jämför speciellt struktur, fokus och formuleringar.
Kategori 1 - texterna är helt olika.
Kategori 3 - texterna är väldigt olika, men har några likheter.
Kategori 5 - texterna är ganska lika, men har några skillnader.
Kategori 7 - texterna är väldigt lika, men med några få skillnader.
Kategori 10 - texterna är i princip identiska.
Svara endast med någon av de specificerade kategorierna i form av en siffra.
---
Svar bör ges genom att först presentera en kort motivering som underbygger din bedömning,
följt av den relevanta kategorisiffran.
Svara enligt formatet:
Motivering: <motivering>
Betyg: <kategorisiffra>Därefter körde jag igenom alla texterna i mitt lilla dataset. Jag testade med några olika GPT-versioner och temperaturer för att se om även det hade någon påverkan.
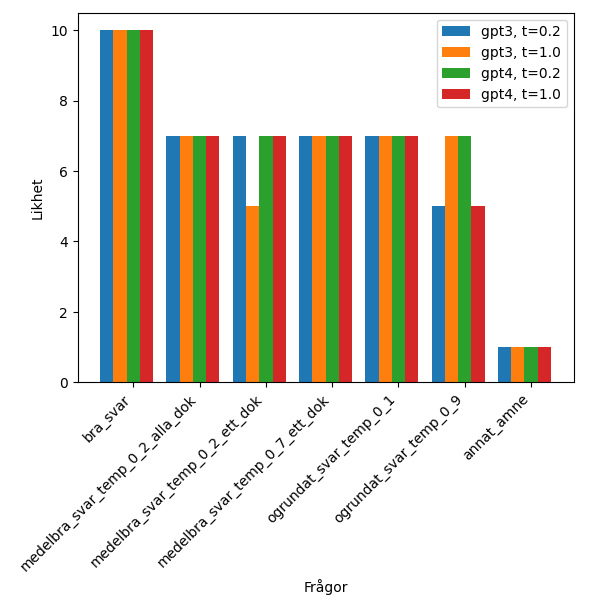
Man hade ju kunnat förvänta sig att LLMerna enkelt skulle pricka in den exakta kopian (”bra_svar”) med en hög poäng och den som var helt annorlunda (”annat_amne”) med en låg poäng – vilket den också gjorde denna gång. Dock är det inte alls säkert att man lyckas med det direkt och därför är det så bra att ha med ytterligheterna (svar ett och sju) för att validera att prompten har en bra grundstruktur.
Resultatet man får beror nämligen mycket på hur man i prompten formulerar vad man tycker är viktigt och som LLMen ska fokusera på. Exempelvis skrev jag i något av alla otaliga försök att “struktur och form” var viktigt och då hamnade alla exempel någonstans i mitten, inklusive ett och sju, eftersom LLMen tyckte att deras struktur och form var väldigt lika min referenstext.
Däremot verkar LLMerna ha uppenbara problem med de olika mellanlägena. Jag har läst att många andra haft problem med att få en LLM att ange betyg eller siffor på en glidande skala. Vilket inte är så konstigt då dom ju faktiskt är experter på text och inte matte. Kategorisering däremot brukar dom vara bra på. Med denna bakgrundskunskap så kanske min formulering i prompten om kategorier nu framstår som mer rimlig.
Alternativa promptar
Jag experimenterade även med lite olika formuleringar och olika upplägg av prompten men fick faktiskt inte fram någon tydlig skillnad mellan de ogrundade och de mellanbra svaren. Det kan bero på att det är svårt att utförligt beskriva vad den ska leta efter. Att få LLMen att förstå ”ganska lika” och ”ganska olika” är ju lite luddigt får man väl erkänna. Men det kan ju mycket väl också vara så att de ogrundade svaren är så pass bra att det är svårt att skilja dem från de medelbra svaren.
Fast då återstår dock frågan hur det kommer sig att vi lyckades identifiera skillnaderna ganska tydligt när vi jämförde embeddings av de olika svaren i de första experimenten. Vi får helt enkelt acceptera att olika mått och jämförelsemetoder funkar olika bra på olika problem. Så det är inte fel att ha lite olika redskap i verktygslådan att plocka från och framförallt testa och jämföra dem på ditt specifika problem.
Framtiden
Utforskningen av AI-förmågan att generera och utvärdera text har bara börjat. Resultaten tyder på att det finns stora möjligheter i att kombinera olika metoder för att skapa ett robustare system för textutvärdering. En kombination av objektiva metoder som embeddings och PCA tillsammans med subjektiva utvärderingar från välformulerade prompts kan ge en mer komplett bild av textkvalitet.