
Ett uppdrag jag roat mig med på sistone är att hjälpa ett företag att svara på en upphandlingsförfrågan. Nu är ju inte upphandlingar mitt specialområde men med hjälp av en LLM så – hur svårt kan det vara?!
Den typ av upphandling det handlar om i detta fall är en ganska rak och enkel variant. I princip består upphandlingen av en bakgrund till projektet samt ett antal frågor på en eller två meningar. Svaret på en viss fråga kan vara allt från några meningar till en halv A4 med text. Företaget jag jobbade med svarar på sådana här förfrågningar 4-6 gånger per år vilket även betyder att de har tillgång till material från tidigare upphandlingar, både underlag och svarsdokument. Svarsdokumenten är 5-10 sidor. Så detta användningsfall skriker ju LLM.
Utmaningen och möjligheten här var att frågorna i upphandlingarna var ganska lika och att informationen man ville få från leverantörerna generellt sett var ungefär samma för alla upphandlingar. Det gäller alltså att ge LLMen tillräckligt med bakgrundsmaterial för att kunna besvara en specifik fråga.
Första försöket
I mitt första försök provade jag att använda ett enskilt svarsdokument samt en fråga.
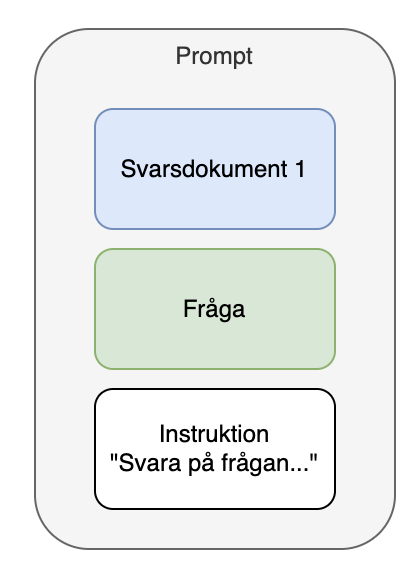
Det fungerade ganska bra. Men längden på svaren var alltid ungefär lika långa oavsett fråga. Även om jag i min prompt-instruktion skrev att jag ville ha en svarslängd som matchade liknande frågor i svarsdokumentet så hjälpte det inte. Att specifikt ange “svara med 500 ord” fungerade nästan. Efter lite mer testande så insåg jag att GPT3.5 som jag körde med här tolkade alla siffor i instruktionen som tokens. (GPT4 däremot förstår konceptet “ord” mycket bättre.)
Så jag testade att köra ett försteg till min riktiga fråga där jag bad LLMen föreslå en lämplig längd på svaret utifrån frågan och grunddokumentet, dvs:

Detta verkade funka och jag fick fram lämpliga svarslängder för mina olika frågor. Senare visade det sig dock att detta var en återvändsgränd – GPT4 klarar av att svara med lämplig längder på svaren baserat på tidigare svarsdokument även utan specifika instruktioner om antal ord. Ok, men då vet vi det nu…
Dessa första svar på några enskilda frågor verkade lovande så vi fortsatte projektet.
All grundinfo
Om man har mycket grundinformation så vill man ju använda den. I detta fall fanns det ju flera tidigare svarsdokument så självklart vill vi ha in denna information i kontexten till LLMen. Så nästa steg att testa var så här:

Det började med totalstopp då kontextlängden var för liten för GPT3.5 så jag fick gå upp till GPT4 med 128k kontext och då gick det bra att köra igen. Det ska tilläggas att jag brukar försöka börja mina experiment med GPT3.5 då den är både snabbare och billigare.
Det man vill testa här är att det blir “bättre” svar (mer om det senare) och att LLMen inte tappar bort sig för att den får för mycket bakgrundsmaterial. Man skulle kunna gissa att en RAG-lösning där man bara plockar ut relevant text och ger som bakgrundsinformation till LLMen kan ge bättre svar. Men som som alltid så börjar vi med den enkla vägen framåt – stoppa in alla kompletta dokument i kontexten o testa!
Bakgrund
Att ge LLMen mer kontext verkade inte fungera sämre i alla fall, men jag upptäckte att det ibland kom med referenser till projektnamnen från de tidigare projekten som ju så klart nämndes i de gamla svarsdokumenten. Detta är ju inte konstigt eftersom ingen talat om för LLMen vilket projekt den aktuella frågan handlar om… Lösningen på det är så klart att lägga till ytterligare grunddokument, specifikt bakgrundsinformation om projektet från upphandlingsdokumentet. Då blev prompten så här:
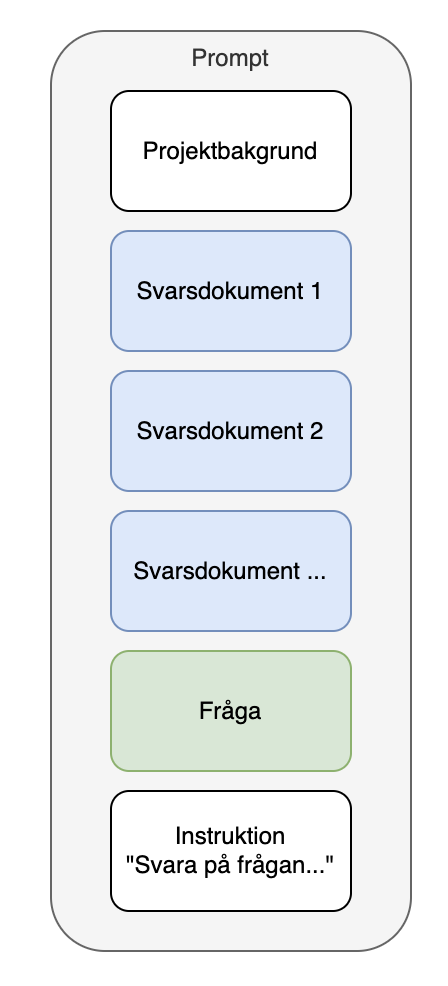
Nu började svaren bli ganska bra med referenser till det aktuella projektet istället för till det gamla, bra svarslängder och relevant innehåll (för det mesta).
Avslutning
När vi nu kommit så här långt så är det dags att gå vidare till nästa fas – utvärdering av svar med hjälp av mätvärden. Genom att variera “LLM-temperatur”, prompt-instruktion, ordning inom prompten, och alla andra hyperparametrar så vill vi ha ett enkelt sätt att mäta om ändringen gjorde svaret från LLMen bättre eller sämre. Detta är lite krångligt med LLMer och kräver en helt egen framtida text – håll utkik i en blogg nära dig!