
Jag tror ingen gillar att läsa avtalstexter, utom möjligen jurister. Ändå är detta något vi utsätts för ganska ofta, kanske inte dagligen, men väldigt ofta. För mig som just bytt bil uppstod återigen det här behovet av att läsa och jämföra olika avtalsvillkor när jag skulle välja bilförsäkring. Efter lite initial vånda kom jag på att det här är ju ett klockrent användningsfall för en LLM (Large Language Model). Att jag även jobbat med andra typer av avtal hos olika kunder gjorde också min startsträcka lite kortare och jag kunde snabbt komma igång med initiala tester. I denna bloggpost ska vi ta itu med just denna utmaning. Med hjälp av en LLM ska vi utföra och analysera en jämförelse mellan två olika villkorstexter för personbilsförsäkringar från If och Länsförsäkringar.
Ett grundantagande är att de flesta försäkringsavtal täcker i stort sett samma vanliga risker och händelser, men när det kommer till de små men ack så viktiga detaljerna så skiljer sig avtalen åt. Just dessa detaljer kan vara avgörande för att du ska få den ersättning du förväntar dig när olyckan är framme. Därför hoppas jag att LLMen ska kunna identifiera alla villkor och undantag och sedan göra en jämförelse baserat på denna information. Ytterligare en utmaning är hur bra LLMen kommer att hantera svenska språket speciellt med tanke på att jag kommer att använda OpenAIs olika modeller i detta experiment.
Man skulle kunna tänka sig två huvudinriktningar för att göra denna jämförelse:
- Skicka in all text för båda avtalen med en superprompt där man ber LLMen hitta alla skillnader.
- Dela upp texten i lagom stora bitar och processa varje del för sig
Alternativ 1
Skicka in all text för båda avtalen med en superprompt där man ber LLMen hitta alla skillnader.
Problem
- Stora textmassor
- superprompt
Fördelar
- Enkelt
Kommentar
Om villkorstexterna är för stora kommer de inte att få plats i en “vanlig” LLMs kontext, som nu för tiden ligger mellan 4k-32k tokens. Dock har OpenAI precis släppt sin nya GPT-4 med 128k kontext (GPT-4-0125-preview), vilket visar sig räcka för mina två villkorstexter. Men med stora texter kan andra problem uppstå, som att LLMen “glömmer” bort vissa stycken i sin indata.
Dessutom är inte superpromptar direkt kända för att fungera, men vi kanske har tur idag?
Alternativ 2
Dela upp texten i lagom stora bitar och processa varje del för sig
Problem
- Mer arbete
- Dela upp texten
- Gör flera LLM-anrop
- Måste själv planera alla steg och deras ordning
- Måste skriva en detaljerad prompt för varje steg
Fördelar
- Måste skriva en detaljerad prompt för varje steg
Kommentar
Genom att dela upp arbetet i flera små väldetaljerade steg kan vi bättre styra exakt vad vi vill att LLMen ska göra, vilket brukar vara en bra taktik. Dock innebär det också en hel del extra jobb.
Kom igång
Jag gillar att börja med det enklaste först för att få snabba resultat, för tänk om det fungerar tillräckligt bra? Då är vi ju klara! Alltså provar vi alternativ ett först.
Prova med alternativ 1
Efter att ha laddat ner avtalen samt extraherat den råa texten så skickade jag in all text med följande prompt:
{system_prompt}
—
Avtalsvillkor LA:
{extracted_text_la}
—
Avtalsvillkor IF:
{extracted_text_if}
—
Jämför de 2 avtalen ovan med avseende på villkor som berör bil.
Sammanfatta i en punktlista hur de 2 avtalen skiljer sig åt
dels för vilka villkor som gäller speciellt i den ena men inte i det andra avtalet,
dels vilka delar som uttryckligen inte täcks av den ena avtalen med som täcks av det andra.
Ta bara med villkor som har med personbil att göra. Ta inte med villkor om husbilar.
Som synes har jag redan här gjort några iterationer för att försöka få bort villkor för husbilar som jag inte bryr mig om här. Här är resultatet.
Jämförelse av avtalsvillkoren för personbil mellan Länsförsäkringar och If Skadeförsäkring:
Villkor specifika för Länsförsäkringar som inte nämns i Ifs avtal:
- Entusiastbil: Länsförsäkringar har specifika villkor för Entusiastbil som inte täcks i Ifs avtal.
- Avställningsförsäkring: Länsförsäkringar specificerar villkor för avställningsförsäkring, medan If inte uttryckligen nämner detta.
- Semesteravbrott: Länsförsäkringar inkluderar semesteravbrottsersättning, inte nämnt av If.
- Vattenledningsskada: Specifikt nämnda i Länsförsäkringars avtal, inte nämnt av If.
- Läckageskada från boutrymmets tank- eller ledningssystem: Täcks av Länsförsäkringar men inte nämns i Ifs avtal.
Villkor specifika för If Skadeförsäkring som inte nämns i Länsförsäkringars avtal:
- BilXtra: If erbjuder BilXtra som inkluderar ersättning för hyrbil, självriskeliminering vid vägassistans, och självriskreducering vid djurkollision och skadegörelse, inte nämnt av Länsförsäkringar.
- VärdeXtra: Specifika villkor för ny bil och förhöjt marknadsvärde som erbjuds av If, inte nämnt av Länsförsäkringar.
- Otur: Specifikt täckt av If, inkluderar ersättning för skada i kupé och bagageutrymme samt för förlorad eller skadad bilnyckel, inte nämnt av Länsförsäkringar.
- Förar- och passagerarolycksfall: If har specifika villkor för ersättning vid medicinsk invaliditet och dödsfall, inte nämnt av Länsförsäkringar.
Delar som inte täcks av Länsförsäkringar men som täcks av If:
- Kristerapi i samband med rån/stöld: If erbjuder ersättning för kristerapi vid rån eller stöld av fordon, vilket inte nämns av Länsförsäkringar.
Delar som inte täcks av If men som täcks av Länsförsäkringar:
- Entusiastbil och Avställningsförsäkring: Ifs avtal saknar specifika villkor för Entusiastbil och Avställningsförsäkring som Länsförsäkringar täcker.
- Semesteravbrott och Vattenledningsskada: Dessa specifika villkor täcks av Länsförsäkringar men nämns inte i Ifs avtal.
Sammanfattningsvis innehåller både Länsförsäkringars och Ifs avtal unika villkor som inte delas av den andra parten. Dessa skillnader påverkar täckningen för personbil på olika sätt beroende på vilket avtal som väljs.
Analys
Det ser ju ganska bra ut vid en första anblick. Men som alltid med LLMer måste man vara försiktig med att lita på dem. För att verifiera resultatet har jag valt att titta extra noga på vad LLMen hittar angående djurkollisioner i de båda avtalen.
När jag lusläser villkoren (vilket jag ju hoppades slippa…) så hittar jag att i följande fall så gäller försäkringen vid djurkollision:
Länsförsäkringar
-Om man har tilläggsförsäkringen MER
If
- Om man har Stor bilförsäkring
- Om man teckat en speciell Djurkollisionsförsäkring
- Om man har tilläggsförsäkringen BilXtra (som inte längre kan tecknas)
LLMen hittade att BilXtra inkluderar djurkollision, men påstår felaktigt att Länsförsäkringar inte nämner detta. Dessutom missar den de två andra möjligheterna man har med If. När man ser närmre på de olika avsnitten i avtalen så bygger de mycket på dokumentets hierarki, vilket är vanligt i avtal. Alltså, för att förstå ett stycke behöver vi veta vilka logiska ovanliggande stycken som finns och vad de innehåller.
- Kanske är hierarkin som blir för svårt för LLMen?
- Eller är det bara för mycket text för att den ska kunna koppla ihop villkor och när de gäller?
- Eller är problemet att både texter och promptar är på svenska?
Förbättringar för alternativ 1
- Skriv om prompten, tex genom att förklara hierarkin eller med exempel på hur hierarkin ser ut, kanske något om att vissa delar är tilläggsförsäkringar och att LLMen särskilt ska hålla utkik efter dessa.
En viktig insikt jag fått genom att experimentera med alternativ 1 är att hierarkin är viktig. För alternativ 2 där min första ansats var att göra en naiv uppdelning av texten i småbitar och sedan i ett antal steg processa den, framstår det redan nu som att det troligen inte kommer att fungera. Utan avtalets hierarkiska kontext kommer villkoren att tas ur sitt korrekta sammanhang.
För att kunna lyckas bättre borde jag nog stryka alternativ 2, och istället fundera kring alternativ 3.
Alternativ 3
Gör en intelligent uppdelning av texten i stycken som tar avtalsstrukturen/hierarkin i beaktande. Detta kan göras genom att de olika kapitlen i avtalen är små nog att rymmas i en LLM-kontext, eller att för alla stycken så tar man även alltid med delar eller sammanfattningar av hierarkiskt överliggande delar ur avtalet. Detta gör att man ger LLMen relevant kontext för de villkor den kommer att arbeta med.
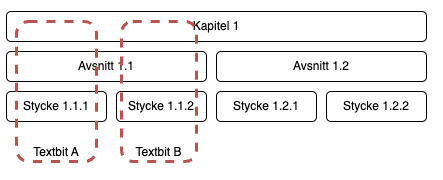
Bilden visar hur man måste kombinera de olika texterna.
Textbit A skulle till exempel kunna innehålla:
- All text från kapitel 1
- All text från avsnitt 1.1
- All text från Stycke 1.1.1
Eller
- Rubriken från kapitel 1
- Rubriken från avsnitt 1.1
- All text från Stycke 1.1.1
Textbit B skulle enligt det första mönstret innehålla:
- All text från kapitel 1
- All text från avsnitt 1.1
- All text från Stycke 1.1.2
Vi skulle alltså behålla kontexten genom att hela tiden spara hierarkiskt överliggande texter tillsammans med textbitar på “lägsta” nivån.
Detta kräver dock mer analys och mer jobb. Kanske borde jag bara läst avtalen direkt istället…
Alternativ 4
Ytterligare ett sätt att angripa dessa avtal på skulle kunna vara följande:
- Dela upp avtalet i lagom stora bitar
- Låt en LLM titta på alla bitar och försöka identifiera alla villkorsområden. Exempelvis borde “djurkollision” komma ut som ett sådant viktigt område från detta steg.
- Generera embeddings (vektorer) för alla textbitar och spara dem i en vektordatabas
- Därefter går man igenom alla villkorsområden och för varje område hämtar man fram matchande textbitar från vektordatabasen
- Låt LLMen jämföra de två avtalen inom ett villkorsområde i taget
- Låt LLMen sammanställa alla gjorda jämförelser
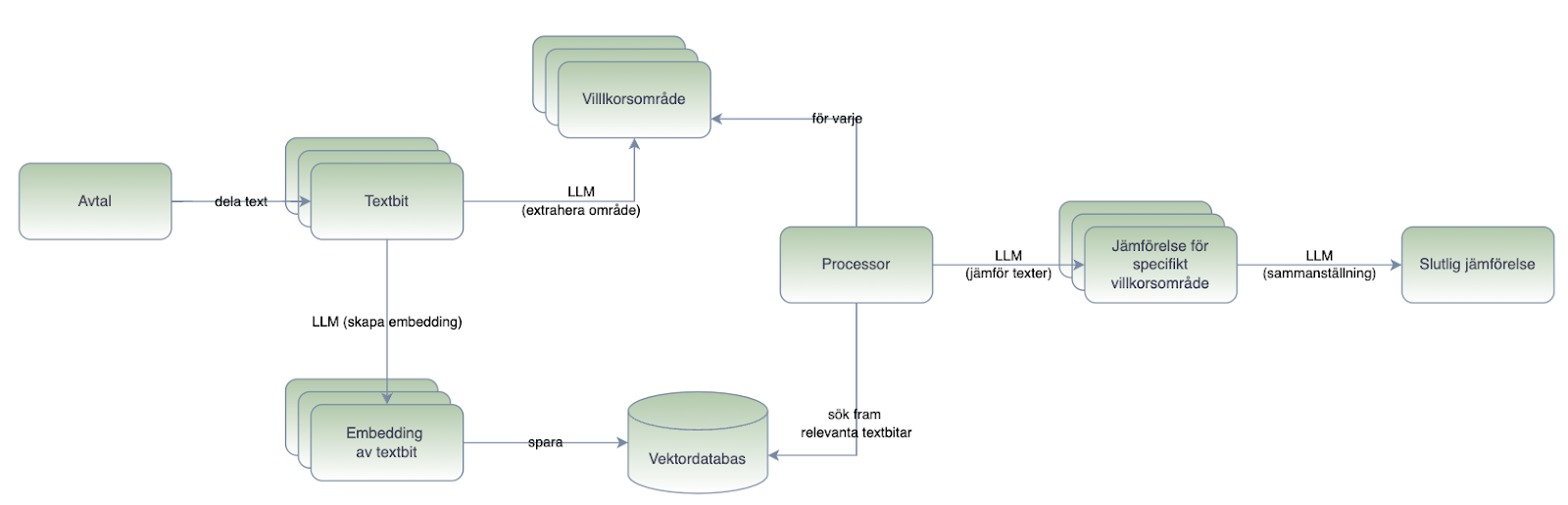
Fördelen med detta är att LLMen kan fokusera på ett enda område i taget och inte blir förvillad av all annan text. Det innebär dock en hel del arbete som synes i bilden ovan. Jämför detta med alternativ 1! Det finns mycket tid och arbete att vinna om den enkla lösningen är tillräckligt bra.
Slutsatser
Som vi såg så är det vanligtvis bra att börja med den enklaste lösningen du kan komma på. Du kommer att få nya insikter under detta initiala arbete, kan skippa återvändsgränder och istället hoppa direkt till alternativen med störst potential. Detta sammanfattar också mycket arbete inom AI, man provar olika saker men vet oftast inte om det kommer att fungera förrän man är “klar”.
Det är alltså inte superenkelt att analysera avtal med hjälp av LLMer. Det krävs en hel del mänsklig analys och förståelse av textmassan innan man kan få någon riktig nytta av LLMerna. Tyvärr – för mig.