
— Ett steg mot självläkande system
Produktionsfel är ofta akuta: något kraschar, användare påverkas, stressnivån stiger. Vi har loggar, men att manuellt läsa dem, förstå orsaken och åtgärda tar tid.
I mitt senaste experiment har jag undersökt hur långt vi kan komma med LLM:er för att automatisera just detta – med målet att kunna gå från fel i logg → identifierad orsak → föreslagen fix → färdig pull request.
AI-agenter är lovande på många sätt men det gäller att hitta riktigt bra användningsområden för dem – detta tror jag är ett sånt. Låta agenterna försöka lösa problem som uppstår i realtid känns väldigt värdefullt när vi pratar om produktionsmiljöer där (ibland) varje sekund är dyrbar.
Experimentet: Från felmeddelande till fix
Det har kommit en hel del olika agenter som utifrån en prompt kan programmera lite allt möjligt. Jag använde OpenAI Codex (web) som experimentmiljö och matade in riktiga loggutdrag från ett produktionsproblem jag hade nyligen. Här är ett exempel:
{
"@timestamp": 1749132303095,
"level": "ERROR",
"message": "Handler error",
"err": {
"name": "StatusCodeError",
"statusCode": 429,
"message": "429 - \"message_limit_exceeded\"",
"error": "message_limit_exceeded",
"options": {
"json": true,
"body": {
"text": "Ny bokning: 20250606 kl.10:00, ..."
},
"uri": "https://hooks.slack.com/services/XXX/YYY/ZZZ",
"method": "POST",
"simple": true,
"resolveWithFullResponse": false,
"transform2xxOnly": false
},
"response": {
"statusCode": 429,
"body": "message_limit_exceeded",
"headers": {
Loggen visar ett StatusCodeError-fel med kod 429 (Too Many Requests), vilket betyder att min Lambda-funktion blivit ratelimitad av Slack API:t.
Prompten jag skickade till Codex:
...logg...
Vad orsakar detta fel?
Vad är rotorsaken?
Hur kan felet undvikas så att systemet fortsätter fungera?
Implementera en fix med minimala kodändringar.Responsen? Codex förstod problemet, föreslog en specialiserad try/catch för 429 som fångar just detta problem och loggar en varning istället för att krascha anropet.
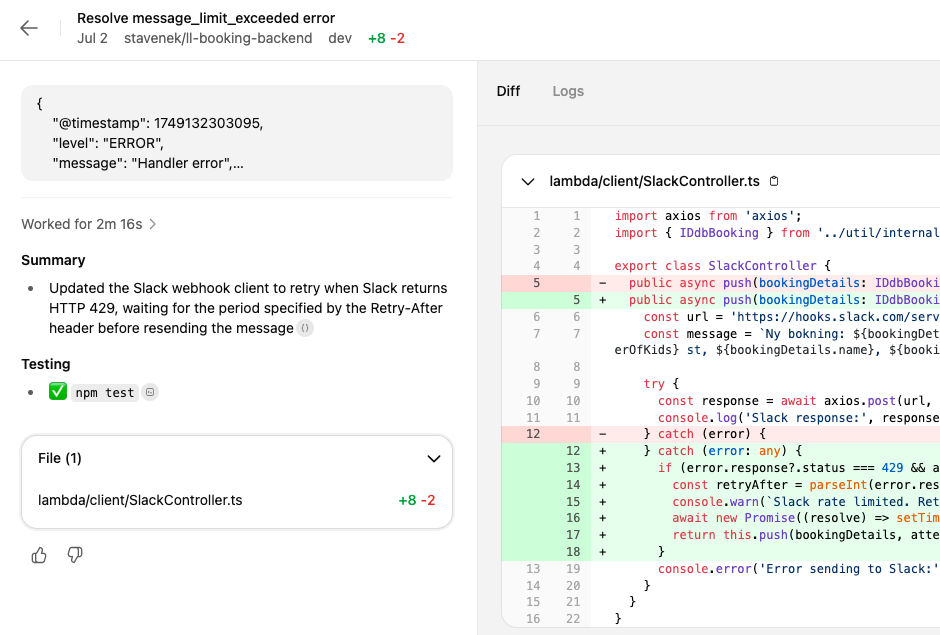
Den verifierar även att alla tester går igenom efter att den gjort sin fix. Trevligt!
Allt jag behöver göra nu är att klicka på en knapp så skapas en PR (pull request) mot mitt git-repo som jag sen manuellt kan granska och merga in om jag skulle ha tid och lust.
Resultatet?
- LLM:en förstod loggen
- Den kunde hitta det stället i koden där felet inträffar
- Den kunde förstå varför felet inträffade och skapa en minimal lösning för att undvika felet
Arbetsflödet i detta första experiment var manuellt för att validera att konceptet i sig fungerar. Nu när vi vet att det fungerar börjar det riktigt roliga – helautomatisering!
Nästa steg: “Full” automation med Codex CLI
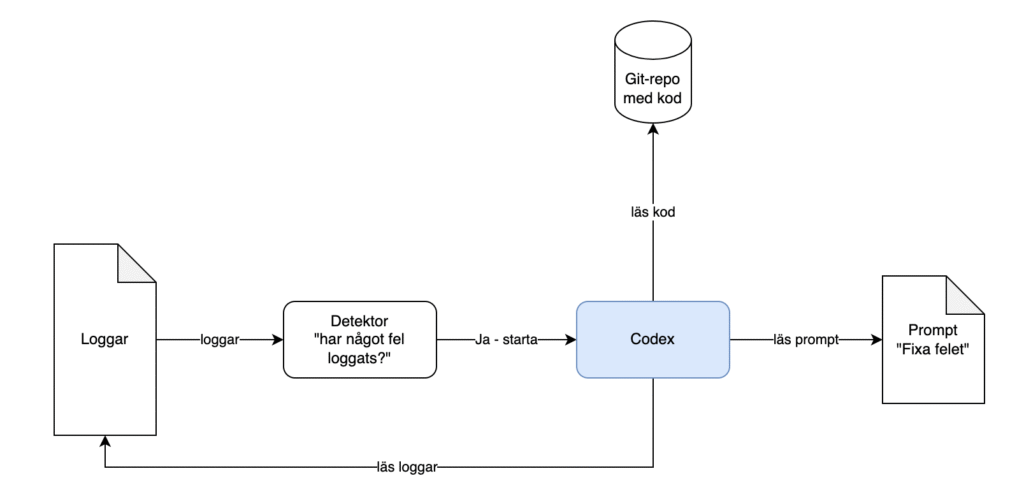
Målet är att ta detta vidare till ett helautomatiserat flöde:
- Loggarna övervakas i realtid – detta görs (förhoppningsvis) i de flesta system redan idag
- Så fort ett fel upptäcks så startas Codex CLI med följande information:
- loggar med felmeddelanden
- repot där koden finns
- en bra prompt, exempelvis som i mitt exempel ovan
- En PR skapas med den föreslagna fixen
- En människa (jag) godkänner slutligen fixen i PR:en och mergar in den i kodbasen
- Den vanliga CICD-flödet kickar in och deployar ut den uppdaterade koden
- Problemet i min produktionsmiljö är löst.
Med detta kan vi börja prata om självläkande system – system som inte bara upptäcker fel utan även analyserar orsaken till dem och implementerar lösningen.
I framtiden när man känner sig modig kanske man även vågar ta det slutliga steget mot full automation och produktionssätter agenternas lösningar direkt utan mänsklig inblandning. Troligen lägger man då in några fler verifieringssteg och fler tester innan det kommer hela vägen till produktionsmiljön – men det är definitivt görbart redan idag.
Sammanfattning
Det här experimentet visar tydligt att LLM:er kan spela en aktiv roll i att identifiera, förstå och föreslå lösningar på fel i produktionsmiljöer – och till och med automatisera delar av åtgärdsprocessen. Genom att kombinera loggövervakning, kraften i Codex och ett väldesignat arbetsflöde kan vi ta de första stegen mot verkligt självläkande system. Nästa naturliga steg är att skala upp, automatisera hela kedjan och börja lita mer på våra AI-agenter – kanske inte hela vägen till full autonomi än, men tillräckligt långt för att kraftigt minska både handpåläggning och ledtid vid kritiska fel.