Du kan bygga en fullt fungerande AI-agent för data analytics på 13 rader kod.
Den läser in en CSV-fil i minnet, du chattar med den, den skriver Pandas-kod och kommer ihåg vad du frågat tidigare.
Några vikiga punkter:
– Ge agenten möjlighet att beräkna saker mha tools och inte bara via LLMen. Det skulle kunna vara en kalkylator-tool, SQL eller Pandas som här.
– Du behöver inte köra den smartaste och dyraste modellen för att få bra analyser – hemligheten med agenter är iterationerna, dvs att agenten skapar en plan i flera steg som den sedan kör och bygger upp sin kunskap och analys med för varje steg.
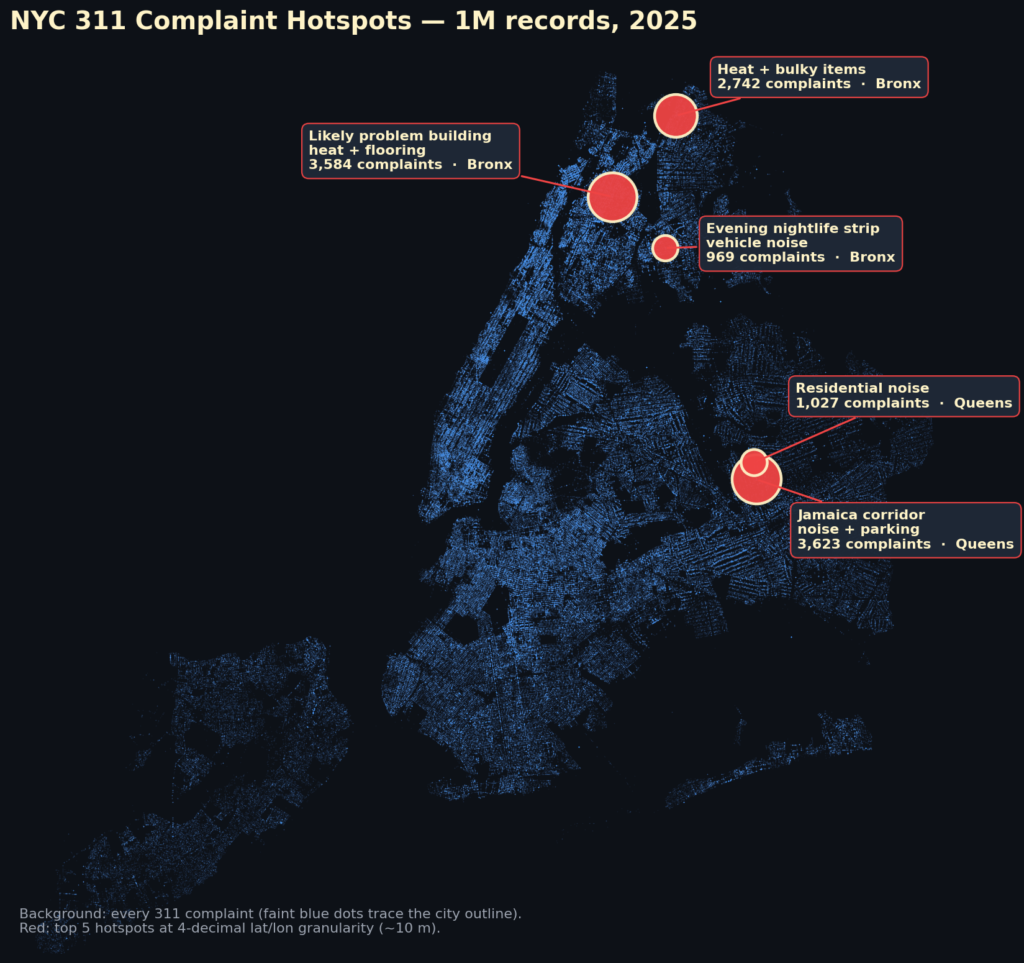
Jag testade mot ett dataset med kundärenden från New York på 1 miljon rader.
1️⃣ Var ligger stadens värsta klagomåls-hotspots?
Agenten kom på att den kunde klippa ner och gruppera lat/lon på 4 decimaler (~10 m) och hittade i princip byggnader med problem.
2️⃣ Topp-3 klagomålstyper per stadsdel:
Bronx domineras av värmeklagomål. Brooklyn och Queens av olaglig parkering. Jag antar att det speglar stadsdelarnas karaktär?
3️⃣ Vad tar längst tid att stänga?
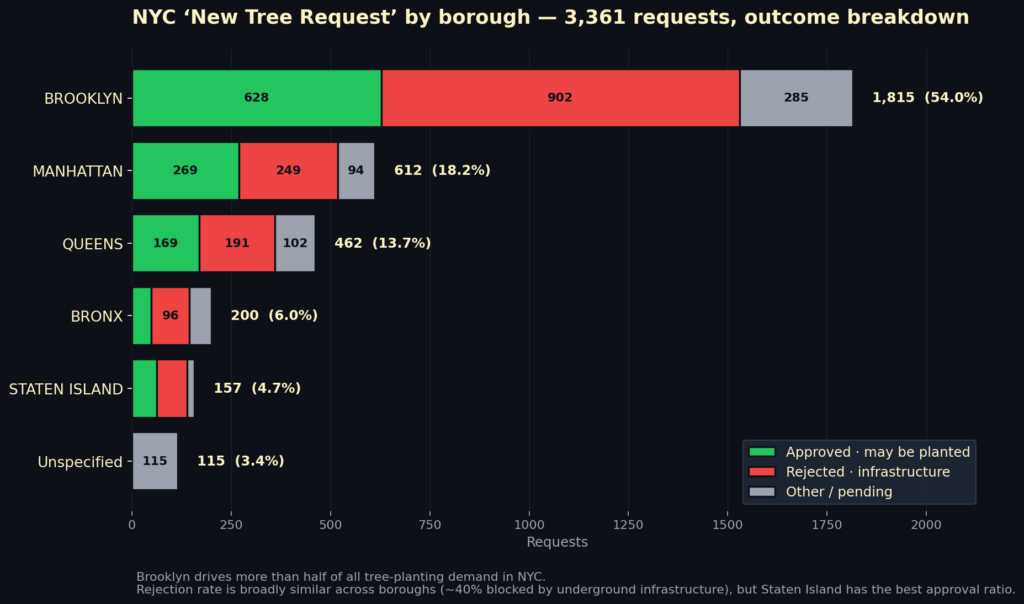
Median för alla: 0,18 dagar (~4 h). Men ”New Tree Request” har 300 dagars median — det blev nästa fråga.
4️⃣ Djupdykning på ”New Tree Request” (3 361 rader, alla från NYC Parks):
▸ Brooklyn står för 54 % av all efterfrågan på nya gatuträd.
▸ 42 % avslås med samma motivering: ledningar under trottoaren ger inte plats för rötter.
▸ Topp-säsong april–maj. Maj ensamt = 1 219 förfrågningar.
▸ Beviljandegrad varierar dramatiskt: Manhattan 44 % ↔ Bronx 24 %. Stadsdelen som klagar mest på värme får minst nya träd…
Slutligen, ja, koden i detta exempel har en eval() vilket inte är så bra säkerhetsmässigt – men OK om du litar på datan du analyserar.
Slutlig insikt – när du väl börjat chatta med din data är det svårt att sluta – det är helt enkelt både kul och fascinerande.
#ai #agentanalytics #LLM #aiagent